


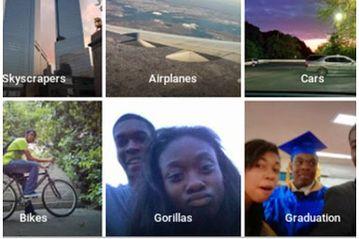
7月3日,谷歌(微博)堪称人工智能和机器学习领域的领军企业,但其Google Photos应用本周犯了一个十分严重的错误,误把两名黑人标注为“大猩猩”。这表明,即使对谷歌来说,人工智能的道路仍然是“路漫漫其修远兮”。
Web开发人员杰基・阿尔西内(Jacky Alciné)发现Google Photos自动把两位黑人的照片标记为“Gorillas”(大猩猩),并截图发布到Twitter上。
阿尔西内在Twitter上说:“Google Photos,你太混蛋了。我朋友不是大猩猩。”
“我们对此感到震惊,并致以真诚的歉意,”谷歌发言人说,“图片自动标记功能显然还有很多改善空间,我们希望今后能避免此类错误再次发生。”
“大猩猩”标签出现在Google Photos应用的搜索功能中。当用户搜索照片时,谷歌会推荐几个由机器学习自动归纳的类别,该公司已经移除了“大猩猩”这一类别,因此以后即使是遇到真的大猩猩照片,也不会有这种提示。Google Photos是谷歌在几周前的I/O大会上发布的新产品。
谷歌首席社交架构师Yonatan Zunger在Twitter上回复阿尔西内说:“我们做了很多工作,但是还有很多问题有待解决。我们会更努力的。”。他还说,谷歌正在努力改善肤色识别技术,在给照片中的人添加标签时将会更加小心。
此事表明人工智能和机器学习技术的不足,尤其是用于普通消费市场时。谷歌通常会发布一些仍然存在瑕疵的产品,然后逐步通过软件更新修正问题。这种模式可以让产品很快推向用户,但如果出现严重漏洞,也会引发用户的不满。
谷歌今年早些时候推出了一款YouTube Kids应用,使用自动过滤器、用户反馈和人工评估的方式过滤成人内容。但该系统仍然放过了一些不当视频,引发了用户的不满。谷歌发言人当时称,“几乎不可能实现100%的精确度。”
谷歌推出Google Photos应用时也承认该应用并不完美,但“大猩猩”标签却集中凸显了这套系统的短板。
人工智能创业公司Sentient Technologies首席科学家巴巴克・霍加特(Babak Hodjat)说:“我们需要彻底革新机器学习系统,以便让其处理更多的背景信息,使之能够理解人类所看重的敏感文化问题。”
他表示,机器学习并不理解不同错误之间的差异,把黑猩猩错看成大猩猩没有问题,但如果把人错看成黑猩猩,就会非常冒犯。
他说,谷歌的系统可能没有“见过”足够多的大猩猩照片以掌握其中的差异,也无法明白这种错误的严重性。
“人类非常敏感,可以发现某些具有重要文化意义的差别,”霍加特说。“机器却无法做到这一点,它们看不到细节,无法理解这种背景信息。”
向谷歌机器学习系统导入更多的大猩猩图片可能有助于解决这个问题,但是这些系统还必须接受训练,方能在特定场合中更加小心。霍加特说,大部分系统经过设置之后,会根据自己的判断给出标签,即使它们本身也并非百分之百确定。
谷歌表示,随着更多的图片加载到Google Photos中,在加上投入更多的人力修复错误标签,这套照片归类算法的效果将逐步提升。谷歌表示,该公司之所以发布这款应用,一定程度上是为了让人们为其提供更多照片,以便提升整体识别率。
谷歌的语音搜索功能也采用了类似的模式。该服务最初有很多识别错误,但随着使用量的加大,识别率已经逐步改善。
Google Photos并不是第一个犯这类错误的软件。雅虎旗下的照片分享网站Flickr在5月推出照片自动识别功能,帮助用户将其上传的照片自动标记归类。雅虎的计算机算法同样不完美,经常会产生偏差。比如把纳粹集中营标记成“运动”。《卫报》报道说,此标记功能也把一位男性黑人标记成“大猩猩”和“动物”。



 举报
举报